


Introduction
When we start with any data project, notebooks are great to explore and experiment various things with the data, be it getting insights from the data, or creating models that generate predictions, or any other task. But once the development part of the machine learning process lifecycle, it's time to move towards the production phase.
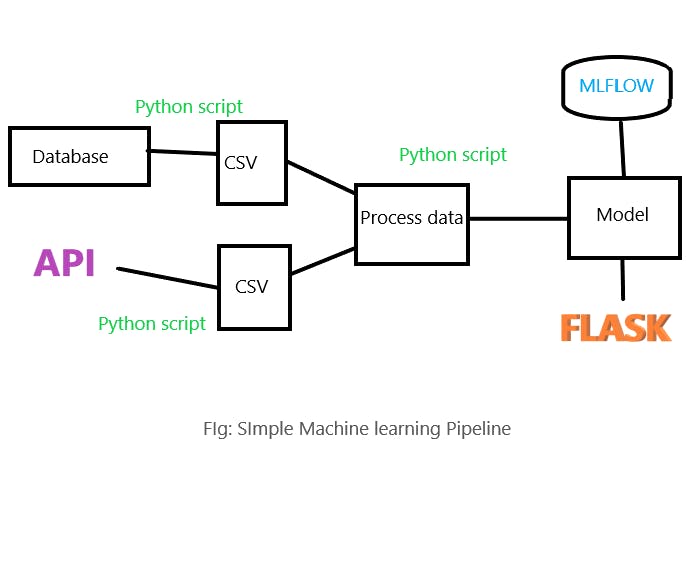
Notebook contains all the steps, from getting the data to the final model we have received as a single step, but during the production any of the steps in the notebook can break down and we may not know about it, in such cases we have to look throughout the notebook to find the error. So, we need to divide that single step into many steps in order to get observability into the steps. Either we write different scripts for different steps and import them as modules and run it, or bring all the code into the same script and run it. We can choose as per our use cases. Now, let’s see what happens once we have deployed our model in the production.
After some time..........................
Looks like our model accuracy decreases after some time, so how do we maintain model accuracy? We retrain new models from time to time, in order to account for data drift. So we have tasks of retraining the model that needs to be automated . Apart from this, let’s suppose we have a machine learning pipeline that we want to run every week. We put it in the scheduler. If the pipeline fails, or any point in the pipeline fails, we want to get observability into the issue that caused them to fail and solve them. There are many points of failure in the pipeline due to interconnectivity. So, if they fail there may be some failure mechanism to initiate. When the API goes down, we can recall that API. We find that most of the time we are coding against failure. This is called negative engineering.
90% of engineering time spent :
- Retries when APIs go down
- Malformed data
- Notifications
- Observability into failure
- Conditional Failure Logic
- Timeouts
Orchestration and Prefect
In this week we will learn about how we can orchestrate these tasks, put them in a scheduler and automate them with a workflow orchestrator. Besides this, when we talk about workflow orchestrators, it provides features that aim to reduce negative engineering. Workflow orchestration is basically a set of tools that schedule and monitor the task that we want to achieve. There are many workflow orchestrator tools and Prefect is one of them.
Prefect is an open source workflow orchestration framework. It is python based. It supports modern data stack, which means the Py data ecosystem. It has native dask integration so we can run our work on top of dask. Prefect is aimed to reduce 90% of engineering time so you can focus more on business problems by eliminating negative engineering.
Features of Prefect
- Embracing dynamic, DAG-free workflows
- An extraordinary developer experience
- Transparent and observable orchestration rules
Now we bring the scripts into prefect by decorating the various functions in the script as tasks and calling those functions turned tasks from the main function, the main function will be decorated as flow, inside which tasks are run. Decorating a function as a task and flow, adds observability around the state of the function during execution.

When we run the above script, a flow run is created to run the flow and tasks are also created inside that flow run. Since Prefect comes with components required to start your own prefect orion server instance locally, when we launch the server from the terminal, it provides an address at which we can visualize our dashboard UI. We can see several flow runs there. Although we have not previously started the server, it’s something that prefect does on its own. Every time we start a flow run, under the hood by wrapping functions as tasks and flow, we are adding observability into it and prefect updates its states into the API, and the API is now shown at the dashboard.
We can start the prefect orion server through the following command
prefect orion start
Deploying flow to prefect orion server
Now lets see how we can automate the tasks and flows.
We achieve automation of flow and tasks by creating a deployment of flow to the prefect orion server with specified deployment specifications, specifying how frequently we run the tasks, how do we run the flow (either normally as a script or inside a Docker or in Kubernetes), where do we store the flow, name of the deployment. We add the deployment specifications on the above script where we have defined our tasks and flow and deploy it as below

Steps for deploying
- Start the server with command
prefect orion start - Create storage to store our flow for future use with
prefect storage create. We get various options to create storage. We can select local storage as well as remote storage. - Create deployment of flow with
prefect deployment create prefect_deploy.py. Theprefect_deploy.pyis the same script described just above with deployment specifications.
Looking at the dashboard, we can see the number of flows scheduled to be run. But those flow runs are not executed yet. Deployment just creates a number of scheduled flow runs but doesn't run it. The execution of the flow run is done by work-queue and agent mechanism. Work-queue specifies the criteria for flow runs to be picked up by a corresponding agent process which runs in your execution environment. They are defined by the set of deployments, tags and flow runners that they filter for. Work queue is just a queue and an agent attached to a work queue. Agent is the one who looks for the work to do every 5 seconds. When it finds work, it unpacks the instructions on how to do the work, it fetches that flow from the storage and runs it.
We can create a work-queue manually from prefect dashboard and view it using the CLI
with the command prefect work-queue preview <work_queue_id from the dashboard>